本ブログは、UiPath米国本社が発表したブログを翻訳したものです。
マルコ・アルバン・イダルゴ(Marco Alban Hidalgo)は、UiPath米国本社の機械学習 プロダクトマネージャーです。
このブログは、データ サイエンス ライフサイクルを運用可能にするために必要となる、一般的な考慮事項を解説する3部構成のブログ シリーズの第1回目です。今回は、組織が機械学習(ML)のジャーニーを始めるための支援をする標準フレームワークを紹介します。
人工知能(AI)を活用することは、さまざまな業界の企業において新たな常識となりつつあります。たとえば、小売業界では、AIを使用して在庫データの履歴から注文を予測することで、インテリジェントに在庫補充の決定を下すことができるようになります。また。カスタマー サポート チームは、優先度の高いカスタマー サポート チケットに対して自動的に応答し、適切なチームに割り当てることにAIを活用することができます。AI、特に機械学習(ML)を活用することにより、具体的なビジネス成果を引き出せる新たな可能性の世界が広がるのです。
Deloitte Insights社によると、エンタープライズ AIのアーリーアダプター(初期受容者)の83%が、実運用プロジェクトの投資利益率(ROI)がプラスとなっていることがわかりました。これらのプロジェクトには、AIを使用したサードパーティのエンタープライズ ソフトウェアの実装、チャットボットと仮想アシスタントの使用、 およびEコマース プラットフォーム用のリコメンデーション エンジンなどの例が含まれていました。調査の対象となった企業の83%が、2019年にAIへの支出を増やす予定と回答しています。また、AIに投資している企業のうち、63%が機械学習(ML)を採用しています。
AIと機会学習(ML)を実践的に活用するための戦略を構築してビジネス目標を達成することは、多くの企業にとって最優先事項となっています。多くの場合、機械学習(ML)の適正な運用を可能にするための主な課題は、組織全体にわたって機械学習(ML)をデプロイする際の管理について良く理解し、計画し、実行することです。
機械学習(ML)運用のために考慮すべき最も重要な点
データ サイエンスのライフサイクルに取り組む「正しい」方法は、組織によって異なります。これまでデータ サイエンスのライフサイクル手順を体系化し標準化するために、多くの試みが行われてきました。ただし、1つのアプローチであらゆる企業のニーズを取り入れることは不可能です。
データおよびデータ サイエンスの持続可能で維持管理性に優れた戦略を採用するという課題は、各企業によって異なり、しかも常に変化し続けています。各企業におけるニーズ、体制、そして能力は、その企業固有のものであるため、企業全体のステークホルダーに助言を仰いだうえで、柔軟でスケーラブルな機械学習(ML)モデルを構築し、包括的なデータ サイエンス戦略を実行する必要があります。
企業によって、対処しなければならない運用上の課題やインフラストラクチャおよび開発プラクティスの変更は内容が異なります。
組織がデータ サイエンスのライフサイクルを定義し進化させる際に、企業文化、システム、および要件を考慮することが極めて重要になります。チーム間で基本フレームワークを共有すれば、コミュニケーションの共通基盤を作るのに役立ち、機械学習(ML)の運用能力を継続的に開発し進化させることができます。
次に、組織が機械学習(ML)のジャーニーを始めるのに役立つ標準フレームワークを見ていきましょう。
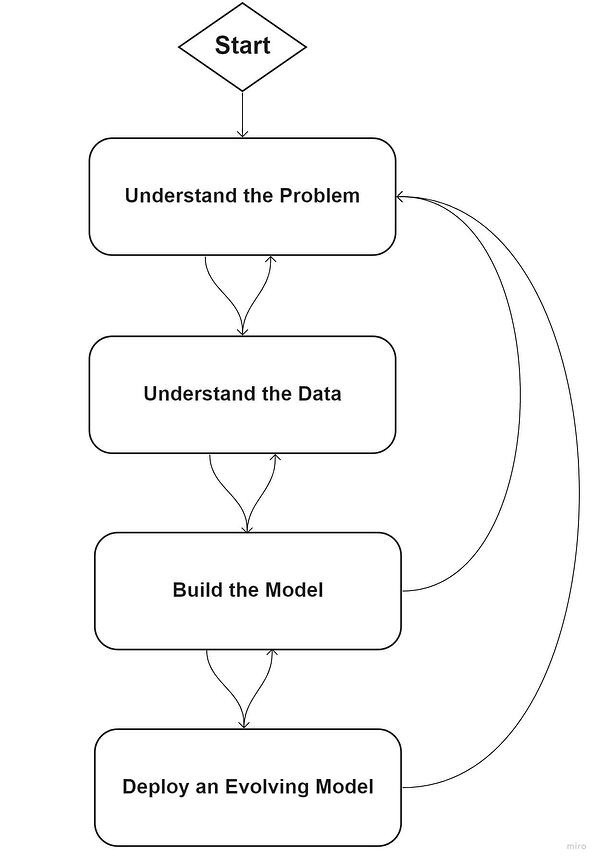
フェーズ1:課題を定義する
どのような機械学習(ML)の新規構想においても核心を突く2つの質問があります。
- 1. どのような課題を解決しようとしているのか?
- 2. 機械学習(ML)があり、データを良く理解さえすれば、当面の課題は解決できると考えるのはなぜか?
上記の2つの質問に対する答えは、会社が戦略をどのように考え、ビジネス上の問題を見極めているかによって異なります。
フェーズ1では、主要ステークホルダーが協力し合って、課題の最初のスコープとその要件を定義します。
フェーズ2:データを理解する
そのデータはどのようなストーリーを持っていますか?データはどこから来たもので、その中でビジネスにおける特定の課題の解決に役立つデータ ソースはいくつありますか?
このフェーズでは、企業は以下の活動に注力します。
● 関連するデータ ソースとそれらが存在している環境のマッピング
(このような環境は、オンプレミスかクラウド内にあり、データウェアハウス、データレイク、またはストリーミングデータプラットフォームとして設定されています)
● 既存のデータパイプラインの定義と、データの検証、クリーンアップ、および調査のために構築する必要があるデータ パイプラインの定義
● データが更新される頻度の理解
● データの信頼性の理解
● データプライバシーの考慮事項と要件の評価
● 生データや変換済みデータの統計的特性、および視覚化などを通じたデータ探索の有効化
データを理解するのは簡単なことではありません。このフェーズには反復的なアプローチを取ることが重要です。データから得られる発見が増えれば増える程、課題解決の能力に影響を与える問題が見えてくることがあります。その場合は、さらにフェーズ1から課題を再定義または再スコープする必要も出てきます。
フェーズ3:機械学習(ML)モデルを構築する
データの準備が整ったら、データ サイエンティストが機械学習(ML)モデルを構築する時です。堅牢な機械学習(ML)モデルを構築するための一般的な手順には以下のものが含まれます。
● 特徴の抽出とエンジニアリング(ビニング、データのホワイトニング、統計的データ変換の適用を含む)
● 特徴の選択
● モデルのトレーニング(データを任意の数のトレーニング、交差検証、および検証用のデータセットに分割することを含む)
● ハイパーパラメーターのチューニング
● モデルの評価
● 統計的有意性の検証
モデルの開発には、ステークホルダーからの継続的なフィードバックが必要です。たとえば、ビジネス上の課題では、特異性に比べて感度への親和性が求められる場合があります。同様に、モデルの運用パフォーマンス(例:より高速な予測)、またはモデルの説明可能性に対して、若干の予測パフォーマンス(例:F1スコア)のトレードオフが起こり得ます。
データ サイエンティストの目標は、データを使用してビジネス上の課題に関連した明確なストーリーを伝えるモデルを構築することです。課題そのものが変貌し、要件も変化するにつれて、モデリングのアプローチも最新のコンテキストに対応するように進化させなければなりません。
フェーズ4:進化するモデルを実装する
初期モデルの構築は、機械学習(ML)ジャーニーの第一歩にすぎません。進化するモデルの実装は、組織の長期的な価値創造にとって重要なステップになります。
そのためには、以下の取り組みが必要になります。
● モデルの提供(モデルの可用性を高め、水平方向にスケーラブルにする)
● モデルのバージョン管理(ロールバックとカナリア/チャレンジャーの実装を含む)
● モデルの再トレーニング(新しいデータがシステムに入力された時点で、モデルを改訂するか新モデルを構築する)
● モデルの監視(提供時とトレーニング時において、運用とユーザー エクスペリエンスの両方の指標を追跡する)
モデルの継続的な成功には、データとモデルのドリフトを監視し、対象となる組織内のユースケースに合わせてモデルを特化する必要があり、他の項目の中でも特にデータパイプラインを維持することが極めて重要です。
企業全体および業界全体での要件は瞬く間に進化し、データソースとその入力に影響を与える可能性があります。たとえば、大規模なガバナンスとコンプライアンスは、データサイエンスのライフサイクル全体に及ぶ考慮事項になります。
欧州連合(EU)の一般データ保護規則(GDPR)などの規制を遵守するためには、データとモデルのバージョン管理、およびモデルの入力レイヤーでのより深いレベルでのトレーサビリティが求められます。これらの業界の変化や要件にデータを通じて対応する戦略を構築することで、企業は引き続き機械学習(ML)を活用して、売上増加、コスト削減、およびリスク低減など、より良いビジネス成果を生み出すことが可能になります。
機械学習(ML)運用の次の展開は?
機械学習(ML)を柔軟で維持可能でスケーラブルな方法で運用するには、このブログで概要を説明した高レベルのスコープを超える、さらに多くのステップと考慮事項が必要になります。 悪魔は細部に宿っているのです。
次回のブログでは、技術的な考慮事項、大規模機械学習(ML)システムのアドホック実装から発生する可能性のある課題について掘り下げ、企業のお客様が一般的な課題に取り組む際にUiPathがどのように支援しているかについて詳しく説明します。
UiPath x AIの連携ソリューションや取り組みについてより詳細を知りたい方は、UiPath x AI Lab Japanへ是非お越しください。

著者について:イダルゴは、スタンフォード大学でAIを専攻し、電気工学の理学士号と、コンピュータ サイエンスの理学修士号を取得しました。修士課程で人工知能を研究し、アンドリュー・エン(Andrew Ng)氏の機械学習コースと、ステファノ・エルモン(Stefano Ermon)氏の確率的グラフィカル モデル コースのティーチング アシスタントを務めました。また、スタンフォード大学経営大学院でMBAも取得しています。